Import Web Content
Train your agent with websites from the internet!
Request Example
Section titled “Request Example”curl --request POST \ --url https://chat.api.toolzz.com.br/api/v2/extractor/upload-web-scraper \ --header 'Authorization: Bearer TOKEN_HERE' \ --header 'Content-Type: application/json' \ --data ' { "unityId": "<string>", "datasetId": "<string>", "folderId": "<string>", "url": "<string>", "limit": 123 }'Response Example
Section titled “Response Example”{ "message": "<string>", "folder": { "id": "<string>", "name": "<string>", "isRoot": true, "knowLedgeBaseId": "<string>" }, "urls": [ {} ], "files": [ { "id": "<string>", "status": "<string>", "fileName": "<string>", "maskName": "<string>", "url": "<string>", "size": 123, "extension": "<string>", "createdAt": "<string>", "kbFolder": { "name": "<string>" } } ]}Request description
Section titled “Request description”Access Token
Section titled “Access Token”| Parameter | Type | Description | Required |
|---|---|---|---|
Authorization | String | Access token (“Bearer” must be before the token) | Yes |
Body Parameters
Section titled “Body Parameters”| Parameter | Type | Description | Required |
|---|---|---|---|
unityId | UUID | Unique identifier of the owning organizational unit. | Yes |
datasetId | UUID | Target Knowledge Base (Dataset) identifier. | Yes |
folderId | UUID | Identifier of the specific folder where the content will be saved. | Yes |
url | URL | The link to the website or web page that will be imported and processed. | Yes |
limit | Number | Optional depth or page limit for scraping. | No |
Response description
Section titled “Response description”| Key | Type | Description |
|---|---|---|
message | String | Confirmation message (e.g., “Web content imported successfully”). |
folder.id | UUID | Unique identifier of the folder where the contents were saved. |
folder.name | String | Name of the folder that received the import. |
folder.isRoot | Boolean | Indicates if the import was made in the root folder of the base. |
folder.knowLedgeBaseId | UUID | ID of the Knowledge Base that owns the content. |
files[].id | UUID | Unique ID of the record generated from the web content. |
files[].status | String | Processing state (e.g., SUCCESS, ERROR, PROCESSING). |
files[].fileName | String | Technical name of the .txt or .html file generated to store the page content. |
files[].maskName | String | Web page title or friendly display name. |
files[].url | URL | Link to the generated file containing the extracted text from the site. |
files[].size | Number | Extracted content size in bytes. |
files[].extension | String | Generated text file extension (usually txt). |
files[].createdAt | String | Import date and time (ISO 8601). |
files[].kbFolder.name | String | Name of the folder associated with the import record. |
urls[] | Array | List of references to the original links sent in the request. |
Security
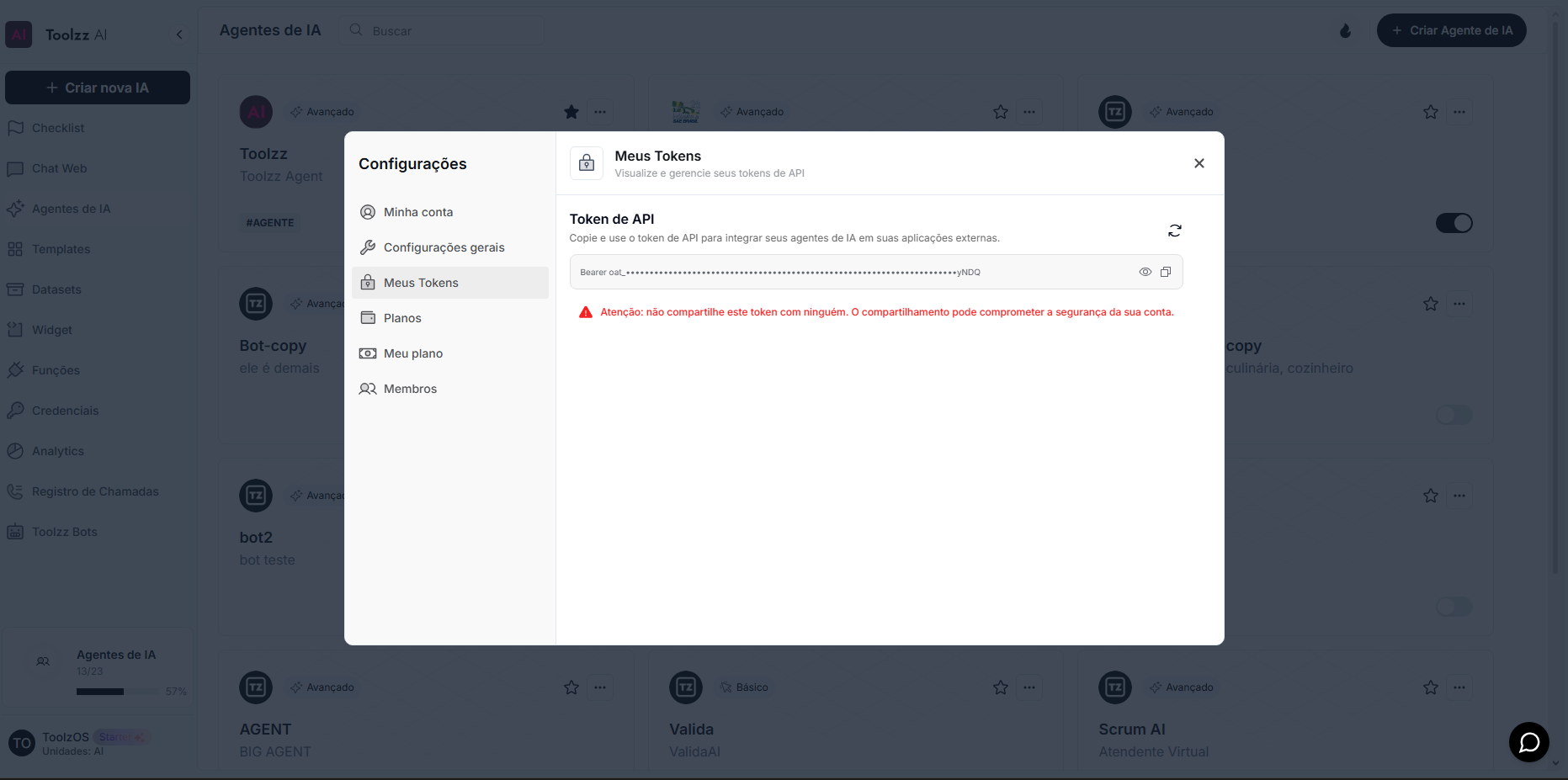
Section titled “Security”To access this endpoint, it is necessary to send a valid access token through the authorization header (Authorization) of the request. Additionally, the API is protected by other security measures to safeguard user data.
To access your access token, follow these steps:
- Log in to the ToolzzAI platform
- Click on “Settings”
- Click on “Access Token”
- Copy the access token